Linux Mint 13 just got released and I have been using it (MATE edition) on my laptop for nearly a week and from my experience, this is a very nice and stable release. However, depending on personal need and preference, users still need to tweak and customize a few things to make it more usable. Here are 10 things that I did after installing Linux Mint 13 - MATE edition.
As always on a freshly installed system, the first thing you need to do is to update the packages. To do so, you can click on the shield icon on the notification area, enter the password and the update manager will appear. Click on the Install Updates button to do the system updating. It will take a while depending on your network speed.

You can also open the terminal and run the following command for system updating:
If your computer has a dedicated graphic card, you should consider installing the proprietary driver for it. When the open source driver does get the job done, it still cannot hold a candle to the proprietary one. To check for available proprietary drivers, open the Mint menu, go to control center then Additional Drivers then select the driver to install. If you are using an ATI card, I recommend you to pick the second driver in the additional drivers window since the first one had caused my system to crash.

After installing the driver, you need to reboot the system for the new driver to take effect.
In Linux Mint 13, Firefox uses two search engines, Yahoo search if you use the search box and DuckDuckGo if you search in the address box. I always prefer Google over these search engines so one of the first things I did after installing Linux Mint 13 was to change the Firefox search engine back to Google search.
To change the search engine in the search box of Firefox to Google, you just need to open Firefox then go to the following address:
After that, click on the drop down list in the search box and select "Add Google"

To change the search engine of the address bar from DuckDuckGo to Google, you open Firefox , type about:config on the address bar. You will see a warning, just click on the "I'll be careful" button to go to the config page. In this config page, scroll down until you find the line that begins with "keyword.URL":

Right click on this line and select the Modify option. The box to edit the search engine will appear, in this box, you just need to replace the DuckDuckGo url with Google:

Click ok and everything is done. Now both the address bar and the search box use Google as the default search engine.
Linux Mint 13 comes with very few themes and icon sets so I think everybody would love to get more themes and icon to decorate the desktop. The best place to look for nice themes and icons in my opinion is Gnome-look. Just go there and search for the themes and icons you like. Also remember to read the installation instruction of each theme and icon set.
Here is my Linux Mint 13 desktop with Delorean Noir theme and ubo icons

Conky is an amazing linux application. A neat conky will make your desktop look amazing. I may be accused of being flamboyant but a conky setup was the first thing I got for my Linux Mint 13 desktop.
Take a look at the awesome Reloj Conky config:

If you are interested in conky like me, you can check my articles about beautiful conky configs.
You can use the Mint Menu to search for and launch applications or access quickly to preferred folders. To customize the Mint Menu, right click on it and choose the Preferences option and the Menu preferences window will open. To add shortcut to your favorite folders, just go to the Places tab and click on the New button to add new folders to the Mint Menu:

To customize the Favorites list on the Mint Menu, you can right click on each application to remove or add it into the Favorite list:

You may find that after you remove some applications out of and add new ones into the Favorite List, the icons arent arranged into the order you want and you cannot drag these icons around on the menu. To change the order of the icons on the Favorites list, you need to edit the file~/.linuxmint/mintMenu/applications.lst. Here is how this file looks to get the Mint Menu in the screenshot below. ( Note: after you edit the applications.list file, you need to right click on the Mint Menu and select Reload plugins to restart the Mint Menu)

Besides the root partition, there are several other partitions in the hard drive of my laptop. These partitions are where I keep my important stuffs. And I hate it when I tried to access a file from an application, I realized that I forgot to mount these partitions. That's why I always prefer auto mounting all the partitions in my Linux box.
There are actually many ways to auto mount partitions in Linux, one of them is to use a tool called "pysdm". First, you need to install it:
Next, open the terminal and run pysdm as root:
The configuration window of pysdm will appear, on which you just need to select the partition to configure:

After that, click on the Assistant button on the right and you will have a menu to customize the behavior of each partition. The option to auto mount partition at booting is the second one.

Just do that to all the partitions you want to mount at booting up and next time, you dont need to manually mount these partition anymore.
By default, the desktop of Linux Mint 13 always displays the icons of mounted partitions and USB drives and I think that makes the desktop ugly. I always want my desktop to be nice and clean. To hide these icons, hit Alt+F2 and type mateconf-editor then hit enter:

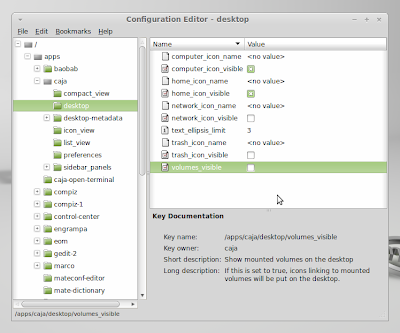
The MATE configuration window will appear. On which, you go to apps > caja > desktop then uncheck the volumes_visible option like the image below:
And you wont see these partition and usb icons on your desktop anymore.
Compiz is an awesome tool, you can do a lot of cool things with it so I recommend everybody to install Compiz. You can tweak a lot of things with CCSM and of course, it is always fun to show the cubic desktops to your friends :D
To install Compiz, you can search for it in the Software Manager or run the following command:
I myself at times need to run some Windows applications so Wine is always a must-have tool for me. To install Wine, you can search for it in the Software Manager or use this command:
These are 10 things I did after installing Linux Mint 13 - MATE edition. If you are using Linux Mint 13 too and have any other ideas, please tell me by giving a comment.
Update System
As always on a freshly installed system, the first thing you need to do is to update the packages. To do so, you can click on the shield icon on the notification area, enter the password and the update manager will appear. Click on the Install Updates button to do the system updating. It will take a while depending on your network speed.

You can also open the terminal and run the following command for system updating:
sudo apt-get update && sudo apt-get upgrade
Install proprietary driver for your graphic card
If your computer has a dedicated graphic card, you should consider installing the proprietary driver for it. When the open source driver does get the job done, it still cannot hold a candle to the proprietary one. To check for available proprietary drivers, open the Mint menu, go to control center then Additional Drivers then select the driver to install. If you are using an ATI card, I recommend you to pick the second driver in the additional drivers window since the first one had caused my system to crash.

After installing the driver, you need to reboot the system for the new driver to take effect.
Change the search engines of Firefox
In Linux Mint 13, Firefox uses two search engines, Yahoo search if you use the search box and DuckDuckGo if you search in the address box. I always prefer Google over these search engines so one of the first things I did after installing Linux Mint 13 was to change the Firefox search engine back to Google search.
To change the search engine in the search box of Firefox to Google, you just need to open Firefox then go to the following address:
http://www.linuxmint.com/searchengine_google.php
After that, click on the drop down list in the search box and select "Add Google"

To change the search engine of the address bar from DuckDuckGo to Google, you open Firefox , type about:config on the address bar. You will see a warning, just click on the "I'll be careful" button to go to the config page. In this config page, scroll down until you find the line that begins with "keyword.URL":

Right click on this line and select the Modify option. The box to edit the search engine will appear, in this box, you just need to replace the DuckDuckGo url with Google:
http://www.google.com/search?q=

Click ok and everything is done. Now both the address bar and the search box use Google as the default search engine.
Get more themes and icons
Linux Mint 13 comes with very few themes and icon sets so I think everybody would love to get more themes and icon to decorate the desktop. The best place to look for nice themes and icons in my opinion is Gnome-look. Just go there and search for the themes and icons you like. Also remember to read the installation instruction of each theme and icon set.
Here is my Linux Mint 13 desktop with Delorean Noir theme and ubo icons

Get a conky setup
Conky is an amazing linux application. A neat conky will make your desktop look amazing. I may be accused of being flamboyant but a conky setup was the first thing I got for my Linux Mint 13 desktop.
Take a look at the awesome Reloj Conky config:

If you are interested in conky like me, you can check my articles about beautiful conky configs.
Customize the Mint Menu
You can use the Mint Menu to search for and launch applications or access quickly to preferred folders. To customize the Mint Menu, right click on it and choose the Preferences option and the Menu preferences window will open. To add shortcut to your favorite folders, just go to the Places tab and click on the New button to add new folders to the Mint Menu:

To customize the Favorites list on the Mint Menu, you can right click on each application to remove or add it into the Favorite list:

You may find that after you remove some applications out of and add new ones into the Favorite List, the icons arent arranged into the order you want and you cannot drag these icons around on the menu. To change the order of the icons on the Favorites list, you need to edit the file~/.linuxmint/mintMenu/applications.lst. Here is how this file looks to get the Mint Menu in the screenshot below. ( Note: after you edit the applications.list file, you need to right click on the Mint Menu and select Reload plugins to restart the Mint Menu)
location:/usr/share/applications/firefox.desktop
location:/usr/share/applications/thunderbird.desktop
location:/usr/share/applications/pidgin.desktop
location:/usr/share/applications/xchat.desktop
separator
location:/usr/share/applications/mate-appearance-properties.desktop
location:/usr/share/applications/libreoffice-writer.desktop
location:/usr/share/applications/mate-terminal.desktop
location:/usr/share/applications/pluma.desktop
separator
location:/usr/share/applications/ccsm.desktop
location:/usr/share/applications/gimp.desktop
separator
location:/usr/share/applications/banshee.desktop
location:/usr/share/applications/vlc.desktop

Set auto mount for all the partitions
Besides the root partition, there are several other partitions in the hard drive of my laptop. These partitions are where I keep my important stuffs. And I hate it when I tried to access a file from an application, I realized that I forgot to mount these partitions. That's why I always prefer auto mounting all the partitions in my Linux box.
There are actually many ways to auto mount partitions in Linux, one of them is to use a tool called "pysdm". First, you need to install it:
sudo apt-get install pysdm
Next, open the terminal and run pysdm as root:
sudo pysdm
The configuration window of pysdm will appear, on which you just need to select the partition to configure:

After that, click on the Assistant button on the right and you will have a menu to customize the behavior of each partition. The option to auto mount partition at booting is the second one.

Just do that to all the partitions you want to mount at booting up and next time, you dont need to manually mount these partition anymore.
Hide the partition icons on the desktop
By default, the desktop of Linux Mint 13 always displays the icons of mounted partitions and USB drives and I think that makes the desktop ugly. I always want my desktop to be nice and clean. To hide these icons, hit Alt+F2 and type mateconf-editor then hit enter:
The MATE configuration window will appear. On which, you go to apps > caja > desktop then uncheck the volumes_visible option like the image below:

And you wont see these partition and usb icons on your desktop anymore.
Install Compiz Config Settings Manager
Compiz is an awesome tool, you can do a lot of cool things with it so I recommend everybody to install Compiz. You can tweak a lot of things with CCSM and of course, it is always fun to show the cubic desktops to your friends :D
To install Compiz, you can search for it in the Software Manager or run the following command:
sudo apt-get install compizconfig-settings-manager
Install Wine
I myself at times need to run some Windows applications so Wine is always a must-have tool for me. To install Wine, you can search for it in the Software Manager or use this command:
sudo apt-get install wine
-------------------------------------------------------------------------------------------
These are 10 things I did after installing Linux Mint 13 - MATE edition. If you are using Linux Mint 13 too and have any other ideas, please tell me by giving a comment.













